
티스토리 뷰
2. 3주차 오늘 배울 것
파이썬으로 웹에 있는 데이터를 긁어올수 있는 크롤링
그것을 저장할수 있도록 mongodb를 활용
03. 연습 겸 복습 - 나홀로메모장에 OpenAPI 붙여보기
article 라는 키안에 리스트가 들어있다.

<script>
$(document).ready(function () {
$('#cards-box').empty('');
listing();
});
function listing() {
$.ajax({
type: "GET",
url: "http://spartacodingclub.shop/post",
data: {},
success: function (response) {
let articles = response['articles'];
for (let i = 0; i < articles.length; i++) {
let article = articles[i];
let image = article["image"];
let url = article["url"];
let title = article["title"];
let desc = article["desc"];
let comment = article["comment"];
let temp_html = `<div class="card">
<img class="card-img-top" src="${image}" alt="Card image cap">
<div class="card-body">
<a href="${url}" target="_blank" class="card-title">${title}</a>
<p class="card-text">${desc}</p>
<p class="card-text comment">${comment}</p>
</div>
</div>`;
$('#cards-box').append(temp_html);
}
}
})
}
function openclose() {
// id 값 post-box의 display 값이 block 이면
if ($('#post-box').css('display') == 'block') {
// post-box를 가리고
$('#post-box').hide();
$('#btn-posting-box').text('포스팅 박스 열기');
} else {
// 아니면 post-box를 펴라
$('#post-box').show();
$('#btn-posting-box').text('포스팅 박스 닫기');
}
}
</script>저번시간에 했던 거랑 비슷하다.
05. 파이썬 기초공부
문법을 다 알 필요가 없고 구글링하는 습관을 기르자
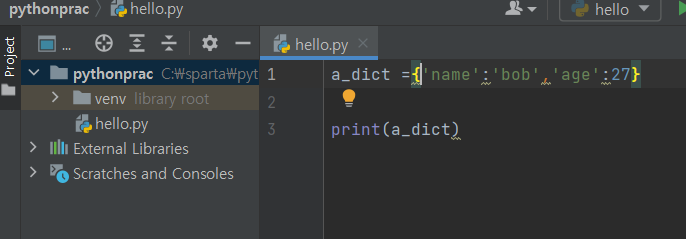
파이썬 기초 문법
변수 & 기본연산


TypeError: can only concatenate str (not "int") to str
인터넷에 구글링 해본다.
원인은 문자하고 숫자를 더하면 에러가난다.
문자열 '2' , str(2)를 고쳐주면 된다.
함수
리스트

딕셔너리

조건문


반복문


대괄호 중괄호 언제 쓰나?
person의 age값을 가져올때는 [ ]를 쓰는구나 이런식으로 이해해야한다.
대괄호는 이럴때 쓰는 거구나 거꾸로 이해하면 아된다.
06. 파이썬 패키지 설치하기
패키지? 라이브러리? → Python 에서 패키지는 모듈(일종의 기능들 묶음)을 모아 놓은 단위이다. 이런 패키지 의 묶음을 라이브러리 라고 볼 수 있다. 지금 여기서는 외부 라이브러리를 사용하기 위해서 패키지를 설치한다.
가상환경 ?
프로젝트별로 패키들을 담을 공구함
라이브러리를 담아두는 폴더라고 생각
pip(python install package) 사용 - requests 패키지 설치해보기
project interpreter 화면에서 +를 누르고 requests 친 뒤 install package를 누른다.
07. 패키지 사용해보기
패키징 어떻게 쓰는지 구글링해보기
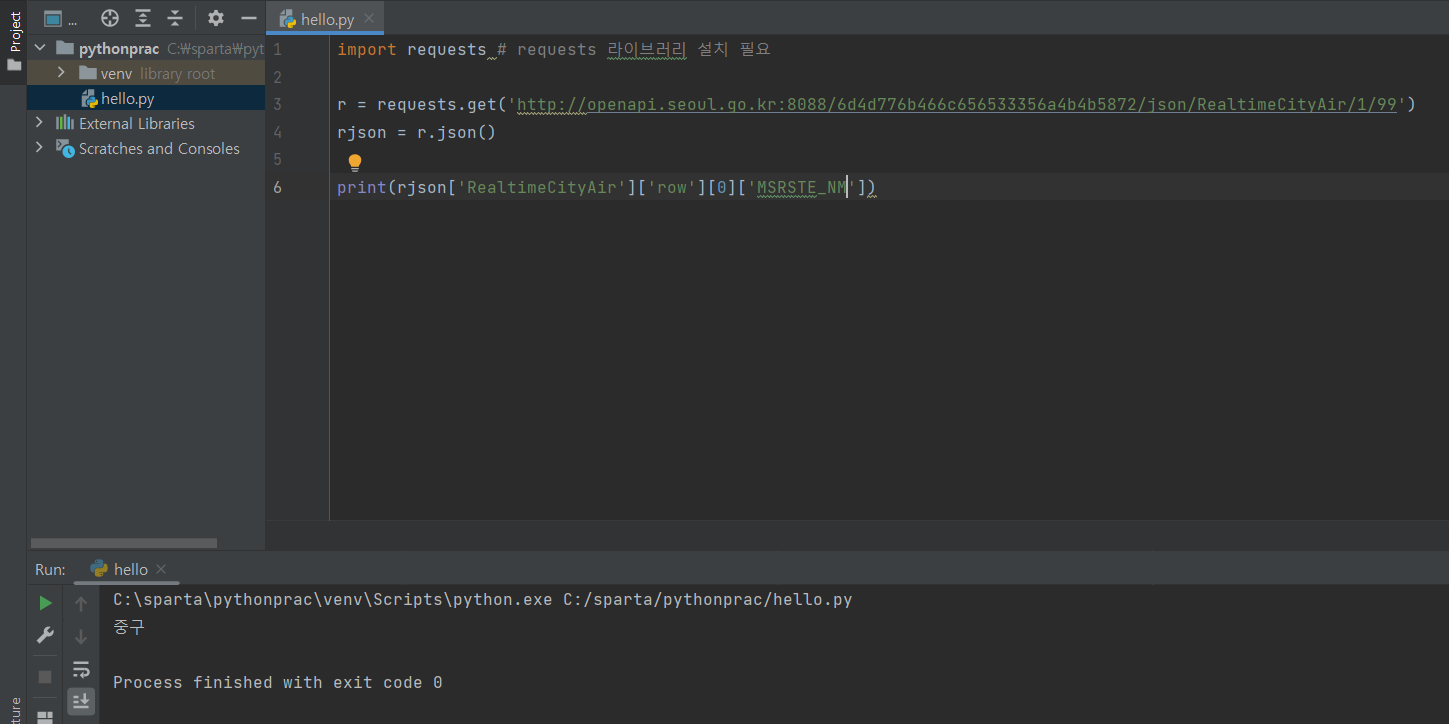
import requests # requests 라이브러리 설치 필요
r = requests.get('http://openapi.seoul.go.kr:8088/6d4d776b466c656533356a4b4b5872/json/RealtimeCityAir/1/99')
rjson = r.json()
print(rjson['RealtimeCityAir']['row'][0]['NO2'])

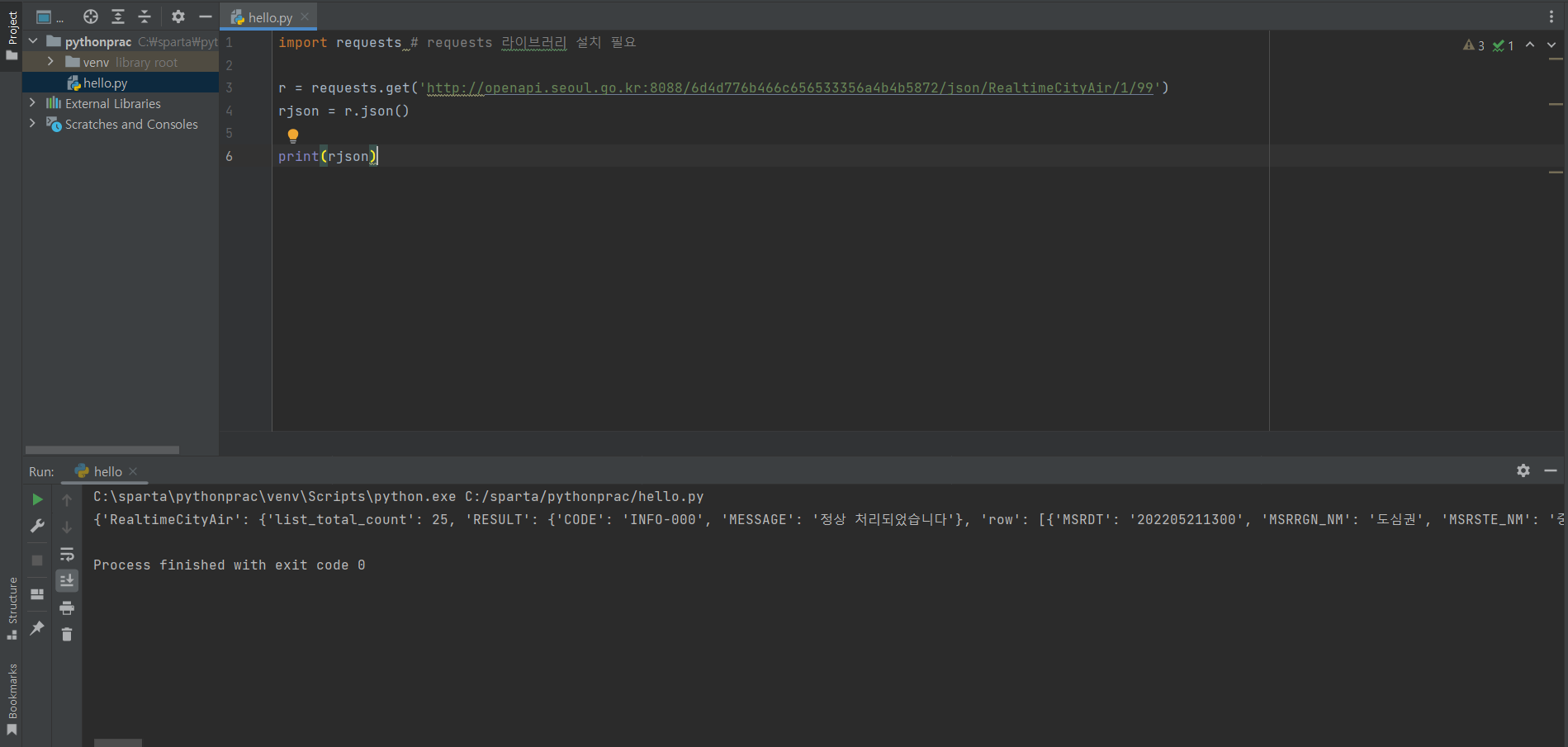
내용은 requests만든 사람이 이렇게 해놨구나 나도 이에 맞게 써야된다고 생각한다.

08. 웹스크래핑(크롤링) 기초
크롤링이란?
구글의 검색 엔진이나 네이버의 검색 엔진이 내 사이트를 퍼가는 행위
크롤링이 가능한 이유?
이미 받아온것을 가지고 내가 쏚아내는것
크롤링할때 중요한기술적인 2가지
1. 브라우저에서 켜지 않고 코드단에서 요청(requests)하는것
2. 요청돼서 가지고 온 hrml들 중에 내가 원하는 정보를 잘 솎아내는 것(beautifulsoup)
기본 코드를 놓고 시작
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
soup = BeautifulSoup(data.text, 'html.parser')
#############################
# (입맛에 맞게 코딩)
#############################print(soup)
headers
코드 단에서 요청했을 때 기본적인 요청은 막아둔 사이트들이 많다.
브라우저에서 enter치는거 마냥 효과를 준다.
url이 들어오고 data로 요청을 받아오면 그거를 가지고 솎아내기 좋은 beautifulsoup형태로 만들어서 찍어준다.
사용방법
select one(한개) 과 select(여러개)
select one
네이버 영화 사이트에서 그린북 검사를 눌러 select 복사를 한다.
selector? 선택자 어디에있는지 정확하게 알려줌



select
html 구조를 보면서 한다.
네이버 영화 사이트에서 그린북 검사를 눌러 <tr>...</tr> select 복사를 한다.

select는 결과가 리스트로 나온다.
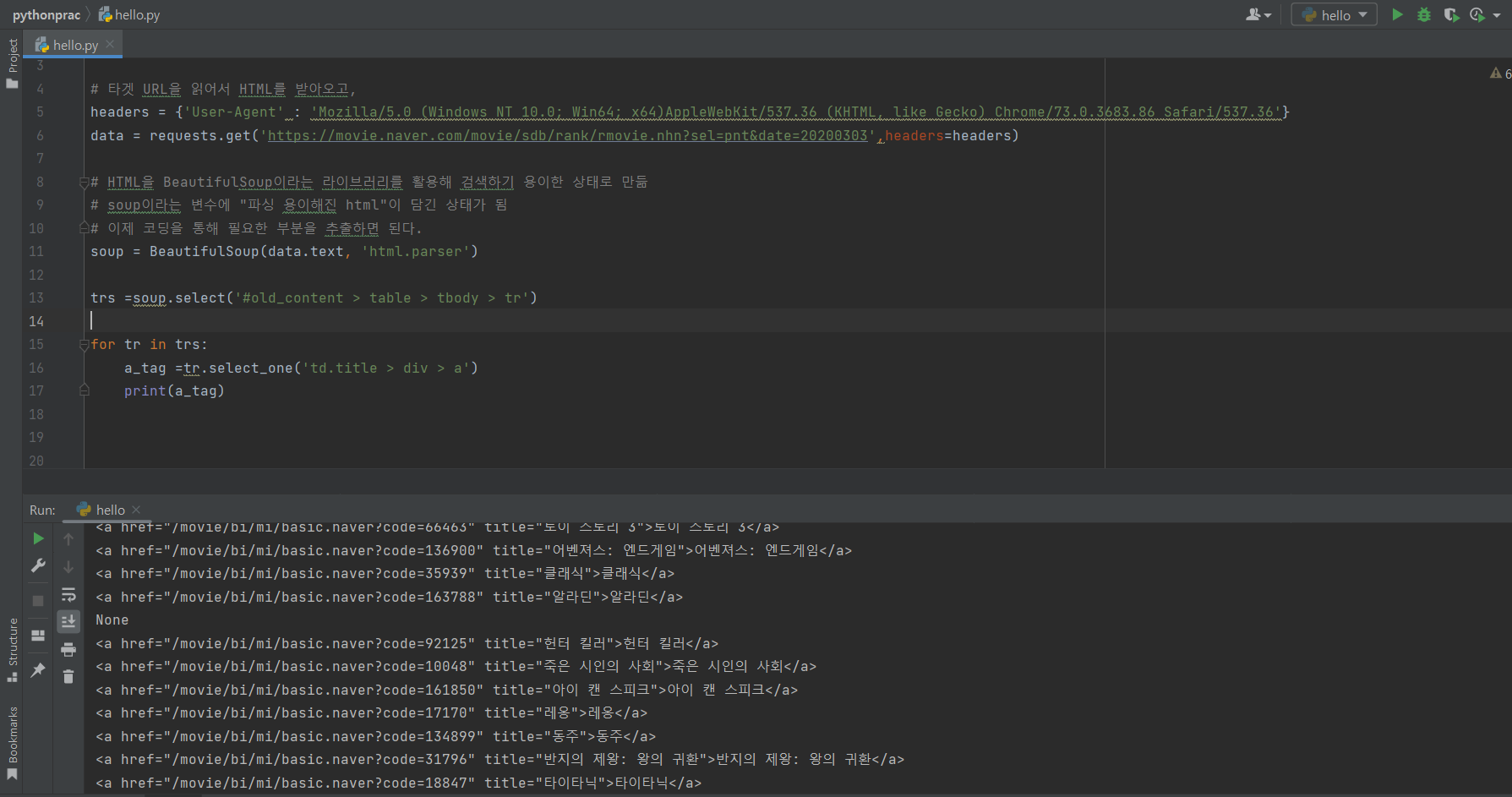

none은 사이트에 있는 줄이다.
줄 안에서 그린북을 가져올라면 error가 난다.
NoneType이 없다 =>None에다가 .text하지말라는 뜻

9강 웹스크래핑 더 해보기 (순위, 제목, 별점)
import requests
from bs4 import BeautifulSoup
# URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
soup = BeautifulSoup(data.text, 'html.parser')
# select를 이용해서, tr들을 불러오기
movies = soup.select('#old_content > table > tbody > tr')
# movies (tr들) 의 반복문을 돌리기
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
rank = movie.select_one('td:nth-child(1) > img')['alt'] # img 태그의 alt 속성값을 가져오기
title = a_tag.text # a 태그 사이의 텍스트를 가져오기
star = movie.select_one('td.point').text # td 태그 사이의 텍스트를 가져오기
print(rank,title,star)
'sparta 웹개발 종합반 개발일지' 카테고리의 다른 글
| Sparta 웹개발 종합반 4주차 1~9강 (0) | 2022.05.22 |
|---|---|
| Sparta 웹개발 종합반 3주차 10~15강+숙제 (0) | 2022.05.21 |
| Sparta 웹개발 종합반 2주차 9~12강+숙제 (0) | 2022.05.20 |
| Sparta 웹개발 종합반 2주차 1~8강 (0) | 2022.05.20 |
| Sparta 웹개발 종합반 1주차 13~16강 +숙제 (0) | 2022.05.20 |